Пока в новостях носятся с экспериментальным 80-ядерным процессором Intel, NVidia окончательно выпустила свой CUDA SDK на прошлой неделе, и можно сказать что stream computing на оченьмногоядерных платформах готов идти, наконец, в массы.
Оба крупнейших вендора представили свои замечательные девайсы и SDK: у нвидии это CUDA, у ATI -- их CTM SDK.
Однако ATI CTM не выглядит так интересно как CUDA, поскольку при всем пафосе он таки слишком похож на третьи-четвертые шейдеры: архитектура и инструкции похожи, лимит на 512 инструкций, и в качестве высокоуровневого языка предлагается HLSL. Правда спецификации очень подробны, и железкой управлять можно очень тонко. На данный момент ATI предлагает все писать на железко-зависимом ассемблере, и считает это почему-то преимуществом CTM.
А вот CUDA от NVidia намного интереснее. С точки зрения девелопера оно выглядит как натуральный очень-многопроцессорный девайс, причем логикой распараллеливания программы можно управлять (в отличие от шейдеров и CTM).
Вообще рекомендую полистать замечательный мануал к CUDA, за что определенно можно любить NVidia -- так это за красивые понятные и подробные SDK. Будущее параллельных вычислений -- на пальцах и с картинками.
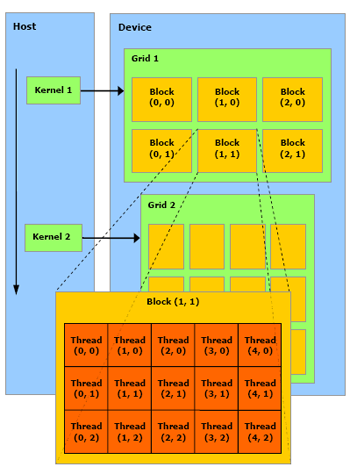
Что, кроме всего прочего, позволяет ожидать кучи параллельных функциональных языков под нвидиевские девайсы ;)




6 comments:
Вот насчет "глубины вызовов" я бы не обнадеживался. Рекурсивных вызовов нет, а вызовы функций - инлайнятся.
Итить... не знаю как для чего, а вот для нейросеток моих это хорошо...
Не так давно пробегало, что можно использовать часть видеопамяти нвидевских карт под свои нужды. Руки чешутся использовать ещё и процессор видеокарты - под мою обработку изображений должно быть самое оно. Ждём и надеемся :-)
Alex Tutubalin>
Ну, секундочку, почему инлайнятся -- даже в шейдерах третьих есть настоящие вызовы функций, глубиной до 4-х -- правда, действительно непонятно почему у шейдеров лимиты документированы а тут нет..
virens>
Насчет памяти не слышал как раз, а вот GPU под разные задачи интересные использовать можно давно -- см. www.gpgpu.org, и под обработку изображений в том числе. Я и DCT видел на них, и DWT, и edge detector'ов кучу (у меня собственно у самого специальность -- обработка изображений :)
Ну потому что инлайнятся.
Попробуйте вынести body в отдельный файл - тут же обругают компилятором.
Собственно, вот:
http://forums.nvidia.com/index.php?showtopic=28612
Mark Harris (NVidia):
Currently all __device__ functions are automatically inlined, so the inline keyword is redundant.
А мне кажется, что CTM очень даже интересно, к тому же в Fusion с ним видимо жить придется :о))
Только SDK я как то не увидел - может кто ссылочку выложит?
или мыльте на sheerai@mail.ru
Post a Comment