Часть курса по процессорам и компиляторам из японского Tohoku University -- написание маленького оптимизирующего компилятора CAML.
Курс вообще отличный, сижу и завидую черной завистью -- сначала студенты разрабатывают процессор на ПЛИС с системой команд от SPARC (вплоть до реализации в железке), потом пишут для него компилятор, и соревнуются у кого быстрее работает тестовое приложение -- рейтрейсер.
Собственно по компилятору можно скачать и лекции, и исходники с подробнейшим описанием всех стадий процесса компиляции и что и как там работает (один минус -- непосредственно в коде комментарии на японском, но там достаточно и других док).
Sunday, March 18, 2007
Компилятор CAML в 2000 строк
Tuesday, March 06, 2007
Очень параллельные языки
В продолжение к предыдущему посту, как пример параллельного языка который мог бы неплохо лечь на GPU (с серьезными изменениями конечно) -- ZPL.
Намного более дружественный синтаксис чем у APL (не нужна специальная клавиатура :), и даже чем у его диалектов J и K.
Выглядит вот так:
region R = [1..n, 1..n ];
RowVect = [ * , 1..n ];
ColVect = [ 1..m, * ];
var M: [ R ] double;
V: [ RowVect ] double;
S : [ ColVect ] double;
[ ColVect ] S := +<<[R ] (M * V);
Замечательное введение в ZPL в комиксах можно смотреть тут.
В общем-то влияние APL на него чувствуется весьма, жалко в отличие от J он функциональным таки не является.
Зато есть функциональный язык NESL, умножение матрицы на вектор на нем выглядит вообще довольно непримечательно для тех кто видел какой-нибудь непараллельный функциональный язык:
sum({v * x[i] : (i,v) in row});
Что неудивительно, поскольку любой функциональный язык, все эти filter'ы и map'ы просто так и просят чтоб их распараллелили.
Ну и естественно Data Parallel Haskell наше все:
smvm sm vec = [: sumP [:x * (vec!:col)|(col, x)<-row :]|row<-sm:]
Thursday, March 01, 2007
Stream computing уже здесь
Пока в новостях носятся с экспериментальным 80-ядерным процессором Intel, NVidia окончательно выпустила свой CUDA SDK на прошлой неделе, и можно сказать что stream computing на оченьмногоядерных платформах готов идти, наконец, в массы.
Оба крупнейших вендора представили свои замечательные девайсы и SDK: у нвидии это CUDA, у ATI -- их CTM SDK.
Однако ATI CTM не выглядит так интересно как CUDA, поскольку при всем пафосе он таки слишком похож на третьи-четвертые шейдеры: архитектура и инструкции похожи, лимит на 512 инструкций, и в качестве высокоуровневого языка предлагается HLSL. Правда спецификации очень подробны, и железкой управлять можно очень тонко. На данный момент ATI предлагает все писать на железко-зависимом ассемблере, и считает это почему-то преимуществом CTM.
А вот CUDA от NVidia намного интереснее. С точки зрения девелопера оно выглядит как натуральный очень-многопроцессорный девайс, причем логикой распараллеливания программы можно управлять (в отличие от шейдеров и CTM).
Вообще рекомендую полистать замечательный мануал к CUDA, за что определенно можно любить NVidia -- так это за красивые понятные и подробные SDK. Будущее параллельных вычислений -- на пальцах и с картинками.
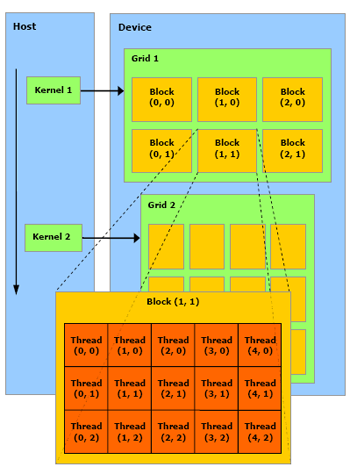
Что, кроме всего прочего, позволяет ожидать кучи параллельных функциональных языков под нвидиевские девайсы ;)
Subscribe to:
Comments (Atom)




{kind=link}